Training an AI agent to navigate operating systems, write code, and run test suites requires competing for the same GPU resources that power its learning algorithm—a fundamental contradiction that has stalled autonomous agent development for years. NVIDIA just engineered the escape hatch.
Context & Background
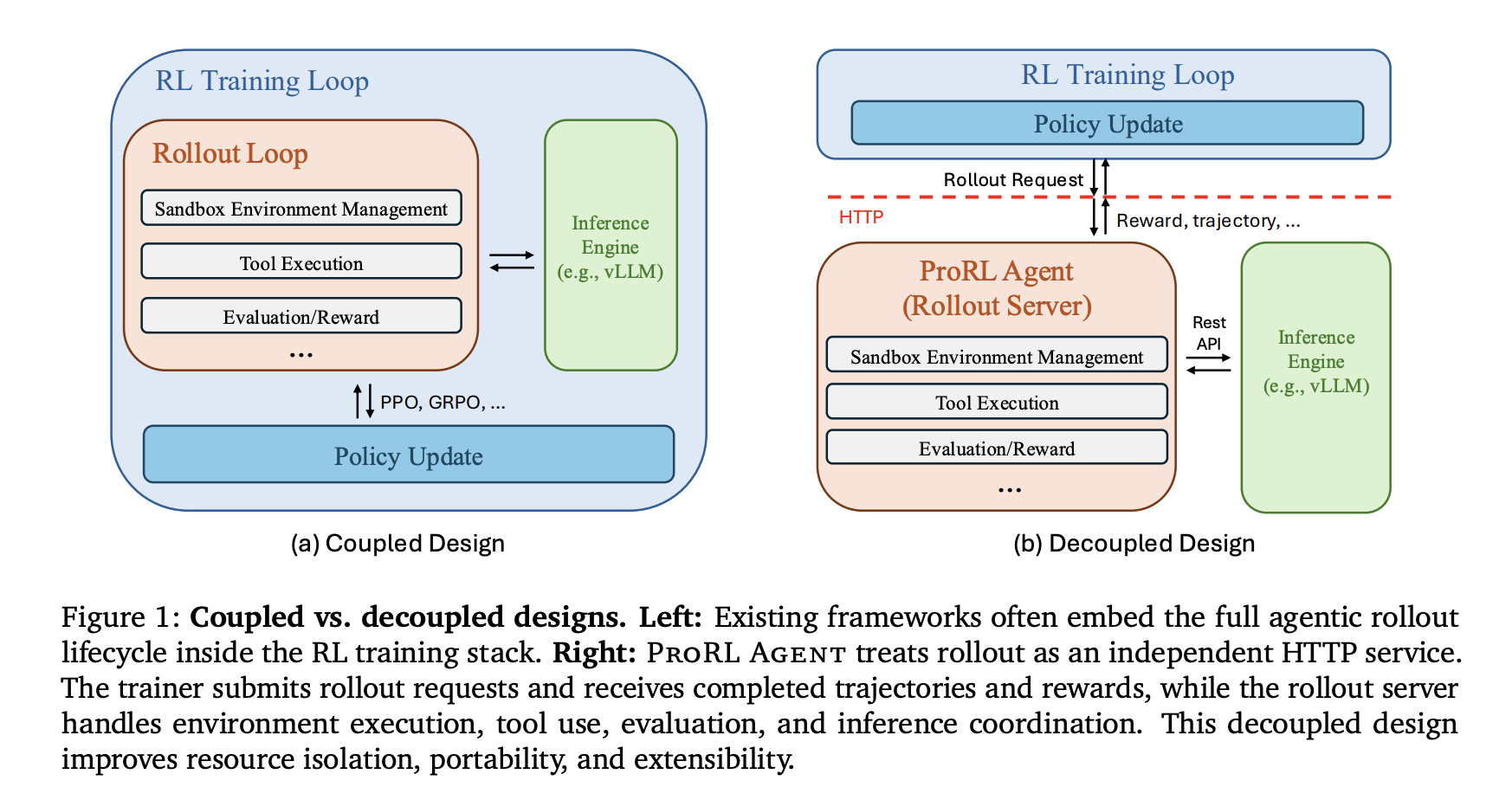
NVIDIA researchers have introduced ProRL Agent, an infrastructure adopting a 'Rollout-as-a-Service' philosophy that decouples agent orchestration from the training loop. The core problem it solves is the resource conflict between I/O-intensive environment interactions and GPU-intensive policy updates. Previous systems including SkyRL, VeRL-Tool, and Agent Lightning embedded rollout control directly within training processes, creating conflicts that reduced hardware efficiency by up to 40% according to internal estimates.
“"By completely decoupling agent orchestration from training, ProRL Agent eliminates the most persistent bottleneck in autonomous agent development."”
Analysis & Impact

ProRL Agent's three-stage asynchronous pipeline represents a fundamental shift in how enterprises and research labs can scale AI agent training. The system operates as a standalone HTTP service where the reinforcement learning trainer interacts solely through APIs, remaining agnostic to underlying infrastructure. This separation allows initialization, execution, and evaluation phases to overlap across different jobs, preventing slow evaluations—like full test suite executions—from stalling the entire rollout process.

