The difference between a helpful assistant and an awkward interaction is measured in milliseconds. Salesforce AI Research just released an architecture that could redefine voice assistants in real estate.
The Big Picture
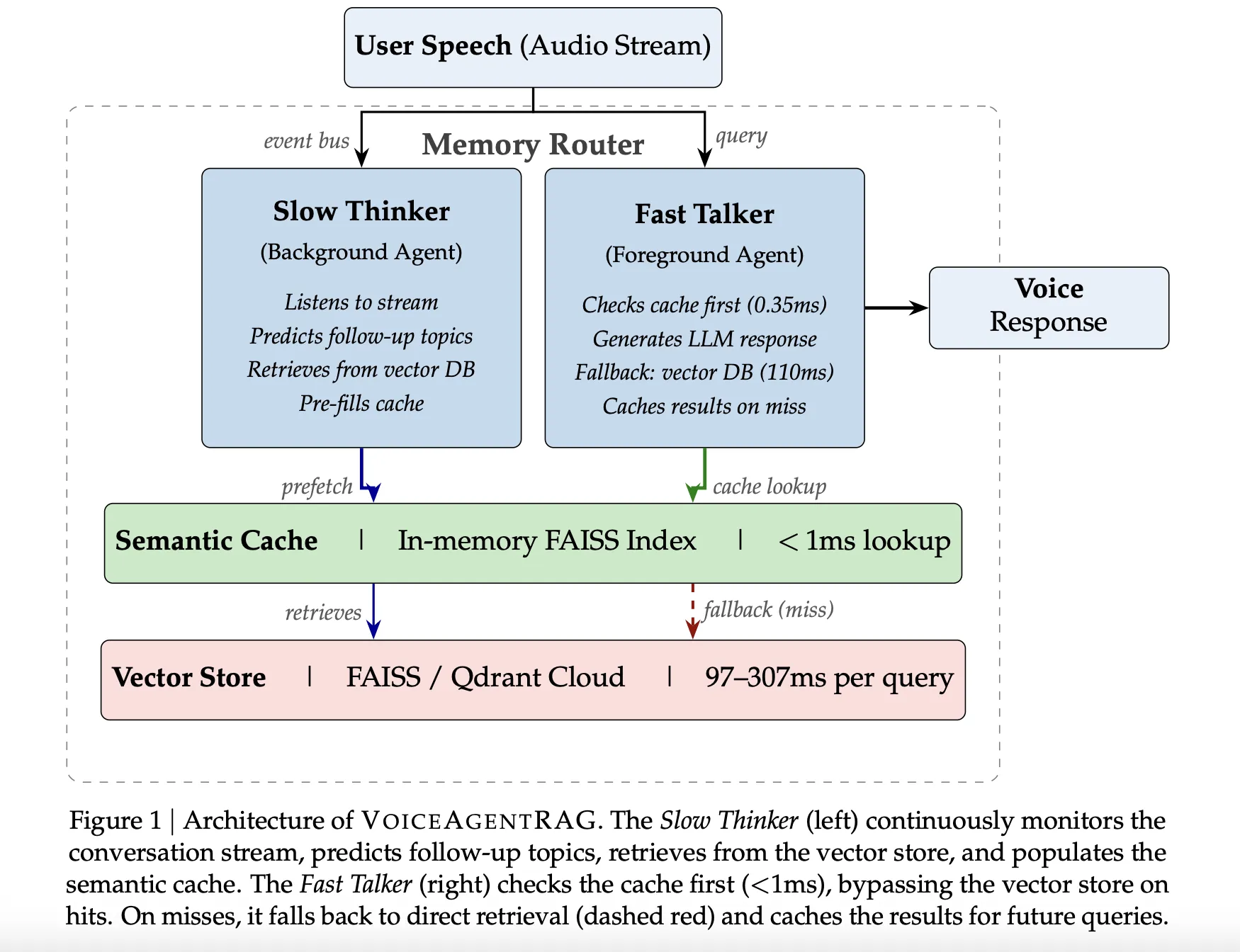
Voice systems operate on a strict budget: 200 milliseconds to maintain natural conversation flow. Standard vector database queries consume 50-300ms in network latency alone, leaving little time for the language model to generate responses. VoiceAgentRAG solves this bottleneck with a dual-agent architecture that decouples document fetching from response generation.
The research was evaluated using Qdrant Cloud as the remote vector database across 200 queries and 10 conversation scenarios. The system is open-source and compatible with major LLM providers.
>A dual-agent system cuts retrieval latency from 110ms to 0.35ms, a 316x improvement.
Why It Matters

In real estate, voice assistants could transform client experience. Imagine asking about mortgage rates, comparing property features, or requesting municipal permit information and receiving instant, accurate responses. Until now, latency made these interactions awkward or outright unworkable.
VoiceAgentRAG achieved a 75% cache hit rate (79% on warm turns). In coherent scenarios like 'Feature comparison,' it hit 95%. In more volatile conversations like 'Existing customer upgrade,' it dropped to 45%. The system saved over 200 turns.

