Microsoft just released three text embedding models that redefine multilingual search. For AI developers and proptech companies, this marks an inflection point in how documents and queries across languages get processed.
The Big Picture
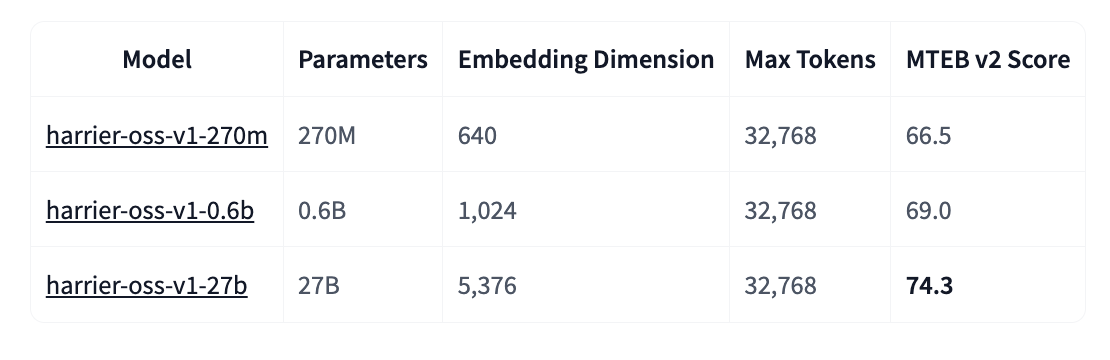
The Harrier-OSS-v1 family represents a radical departure from traditional architecture. For years, embedding systems like BERT have dominated the landscape, using bidirectional encoders that process all context simultaneously. Microsoft opted for decoder-only architectures, similar to those powering modern large language models.
This architectural choice fundamentally changes how context gets processed. In a causal model, each token can only attend to preceding tokens. To create a single vector representation of the full text, Harrier uses last-token pooling: taking the hidden state of the sequence's final token and L2-normalizing it for consistent magnitude.
“The 32,768-token context window lets you embed entire documents without aggressive chunking.”
Why It Matters

For real estate and finance sectors where documents run long and multilingual, technical specifications matter. All three models offer 32,768-token context windows, a quantum leap from the 512 or 1,024 tokens typical of traditional models. This means property listings, complex contracts, or market analyses can be processed as complete documents, preserving semantic coherence lost through fragmentation.

