Alibaba just dropped a native multimodal model that processes text, audio, and video in one pipeline. This isn't just another tech upgrade; it's a strategic play in the global AI arms race.
The Big Picture
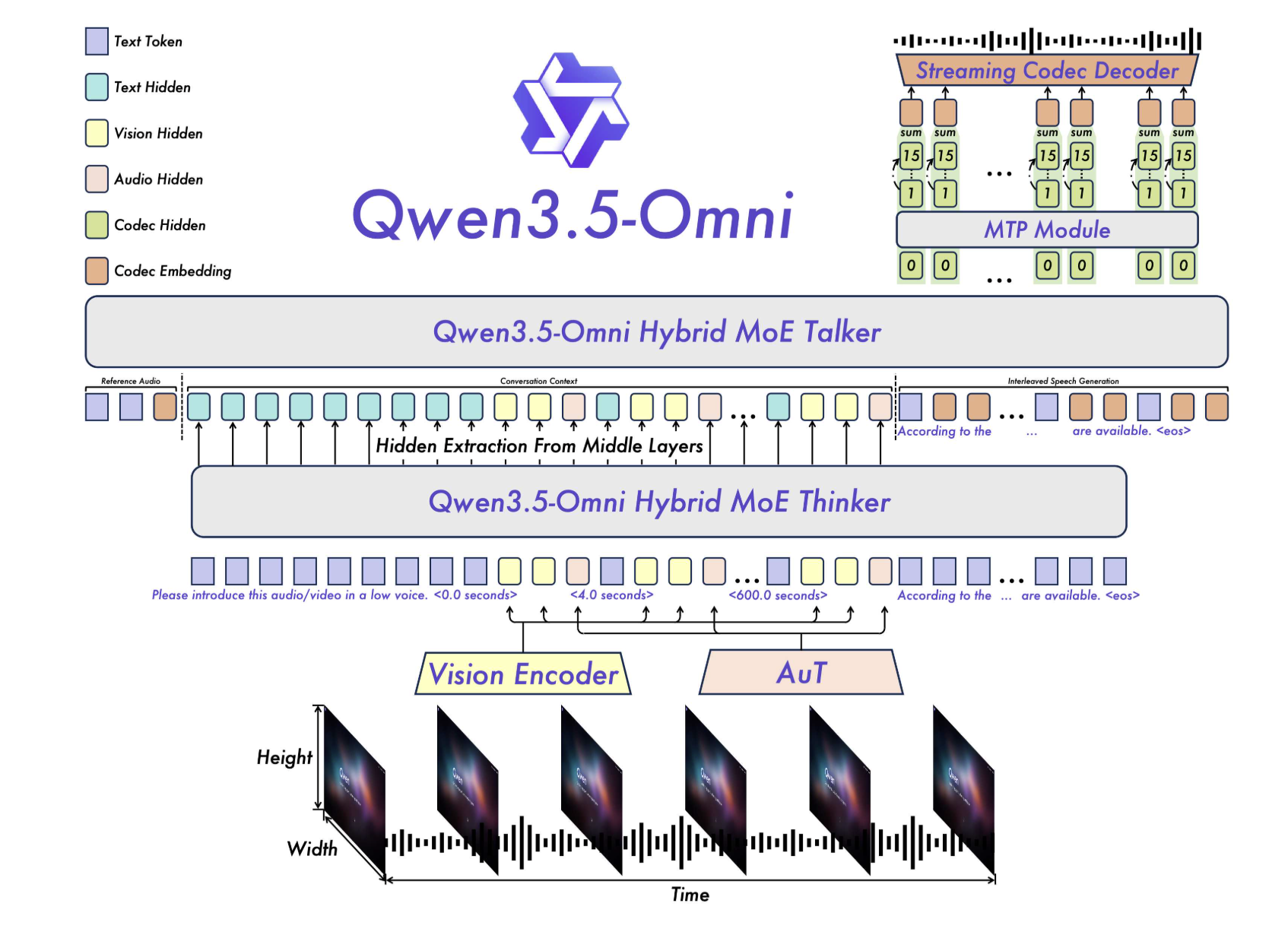
Multimodal AI has evolved from a niche experiment to a core battleground for tech giants. For years, large language models (LLMs) relied on 'wrapper' architectures, where separate vision or audio encoders were stitched onto a text-based backbone. This approach, while functional, introduced latency and integration headaches. The industry has been craving sleeker solutions, especially as real-time applications like virtual assistants and streaming content analysis gain traction.
Alibaba's Qwen team has answered with Qwen3.5-Omni, a model built from the ground up to be 'omnimodal.' It's not a tech patch but a fundamental redesign. Its Thinker-Talker architecture and Hybrid-Attention Mixture of Experts (MoE) allow it to process multiple modalities simultaneously within a single computational pipeline. This positions Alibaba head-to-head with giants like Google and its Gemini 3.1 Pro model, marking a shift in how companies approach multimodality. In a market where speed and accuracy are currency, this launch could reset industry standards.
“A model that nails 215 SOTA results in audio and audio-visual tasks isn't just a tech feat; it's a declaration of war in the AI race.”
Why It Matters


