Mistral AI just released its first text-to-speech model. The French company completes its audio stack as conversational interfaces become critical for real estate and financial services.
The Big Picture
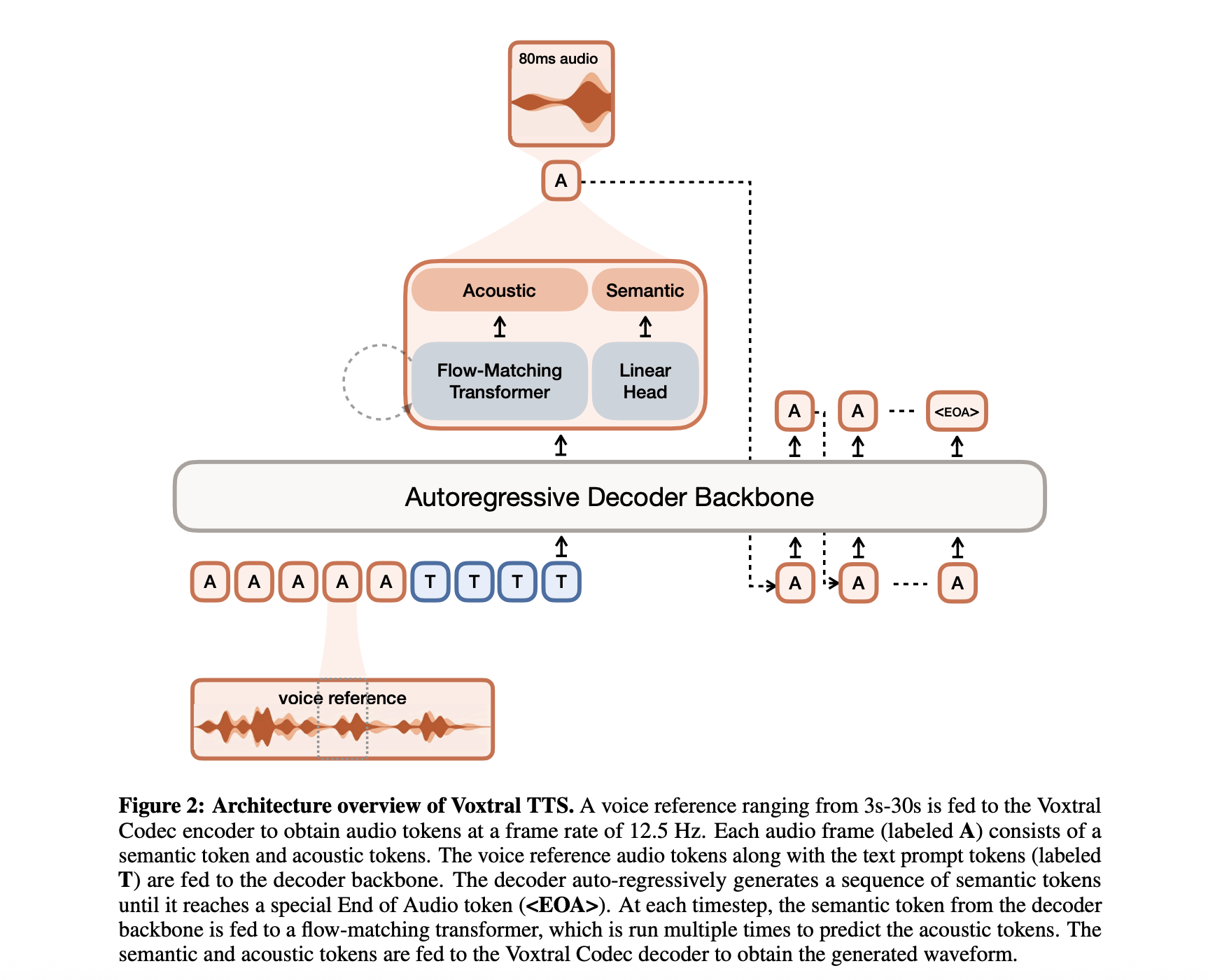
Voxtral TTS isn't just another synthetic voice generator. It's a 4-billion parameter model specifically designed for real-time integration, released under a CC BY-NC license. Mistral continues its open-weight strategy but now targets the expensive proprietary voice APIs dominating the market.
The model's hybrid architecture separates speech meaning (semantic) from voice texture (acoustic). This enables consistency in extended conversations while maintaining the nuances needed for lifelike interaction. For real estate, where inquiries can span minutes, this technical distinction matters.
“A 70ms-latency voice model could make conversational interfaces feel as natural as talking to a human agent.”
Why It Matters

Latency defines production applications. Voxtral TTS achieves 70ms model latency for 10-second voice samples, a threshold that makes it viable for conversational agents and real-time translation. In real estate, where every second of delay means lost clients, this speed could transform customer service and virtual tours.

