NVIDIA Revoluciona IA: ProRL Agent Desacopla Entrenamiento de Agentes LLM
NVIDIA reduce latencia de comandos shell de 0.78s a 0.42s con nueva infraestructura que elimina cuellos de botella en entrenamiento de agentes IA.
Imagine entrenar un agente de IA que pueda navegar sistemas operativos completos, escribir código y ejecutar pruebas—todo mientras compite por los mismos recursos de GPU que su algoritmo de aprendizaje. Esta contradicción fundamental ha frenado el desarrollo de agentes autónomos durante años, pero NVIDIA acaba de desbloquear la solución.
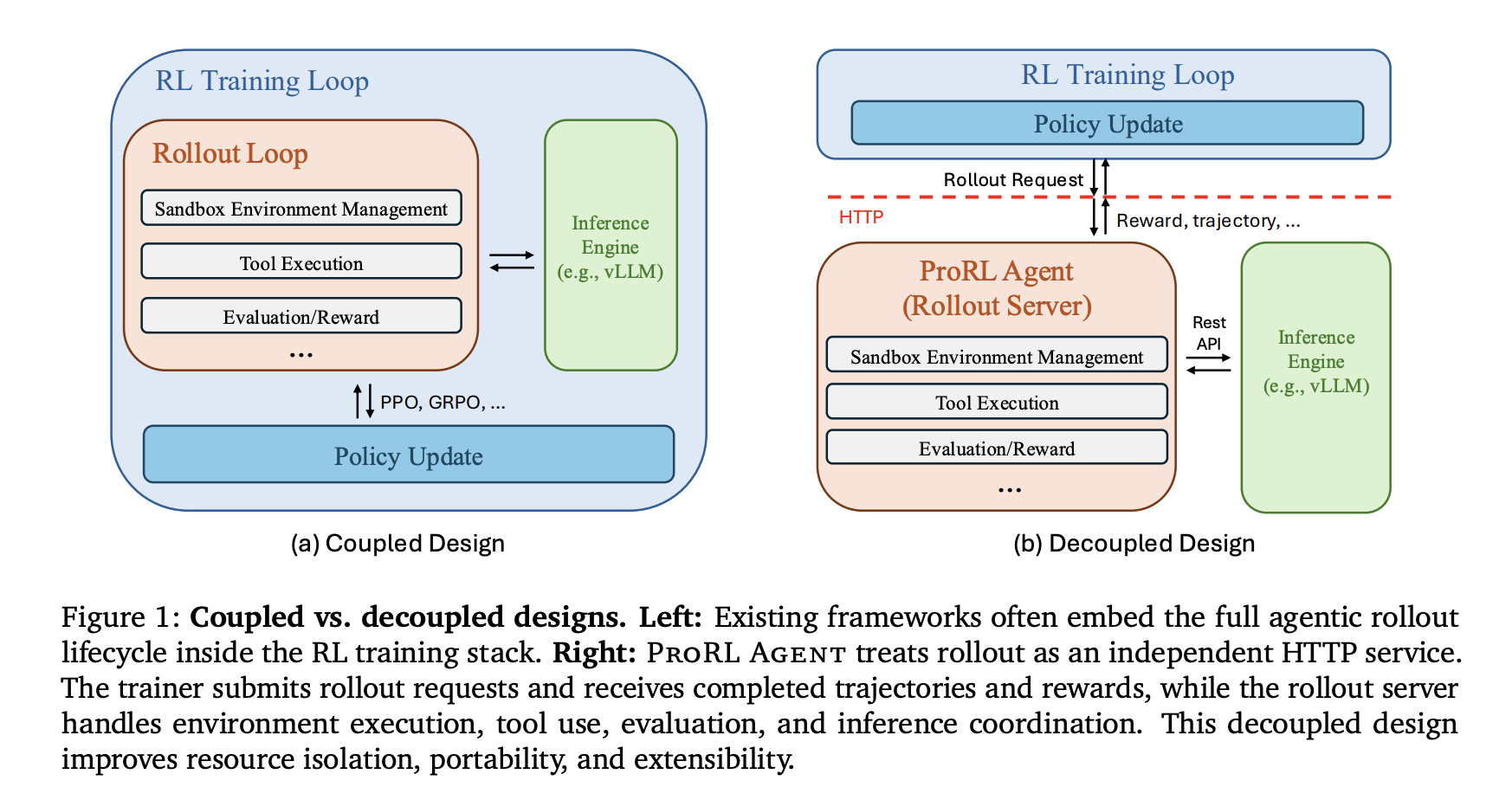
Contexto & Antecedentes Los investigadores de NVIDIA han presentado ProRL Agent, una infraestructura que adopta una filosofía de 'Rollout-as-a-Service' para separar la orquestación de agentes del bucle de entrenamiento. El problema central que resuelve es la dependencia entre procesos intensivos en I/O (interacciones con entornos externos) y procesos intensivos en GPU (actualizaciones de políticas). Sistemas anteriores como SkyRL, VeRL-Tool y Agent Lightning integraban el control de ejecución directamente en el proceso de entrenamiento, creando conflictos que reducían la eficiencia del hardware en hasta un 40% según estimaciones internas.
“"Al desacoplar completamente la orquestación de agentes del entrenamiento, ProRL Agent elimina el cuello de botella más persistente en el desarrollo de agentes autónomos."”
Análisis & Impacto La arquitectura de tres etapas asíncronas de ProRL Agent representa un cambio fundamental en cómo las empresas y laboratorios de investigación pueden escalar el entrenamiento de agentes de IA. El sistema opera como un servicio HTTP independiente donde el entrenador de aprendizaje por refuerzo interactúa únicamente a través de API, manteniéndose agnóstico a la infraestructura subyacente. Esta separación permite que fases de inicialización, ejecución y evaluación se superpongan en diferentes trabajos, evitando que evaluaciones lentas (como ejecuciones completas de suites de prueba) detengan todo el proceso.
La elección de Singularity sobre Docker para la infraestructura de sandboxing es particularmente significativa. Singularity permite ejecución sin privilegios de root, un requisito esencial para despliegues en clusters HPC compartidos gestionados por Slurm—la plataforma dominante en investigación académica y desarrollo corporativo a gran escala. Las optimizaciones de latencia son igualmente impresionantes: el reemplazo de multiplexación basada en tmux con pseudo-terminales directos reduce la latencia de comandos shell de 0.78 segundos a 0.42 segundos, una mejora del 46% que se multiplica a través de miles de iteraciones.
La comunicación mediante Unix Domain Sockets (UDS) dentro de contenedores elimina la sobrecarga de red TCP, mientras que la API directa de IPython se conecta a kernels persistentes sin gateways de red. Estas optimizaciones colectivas atacan el problema más crítico en entrenamiento de agentes: la latencia de herramientas, que típicamente domina el 70-80% del tiempo total de rollout.
La implementación de token-in/token-out communication resuelve un problema sutil pero devastador: el drift de re-tokenización, donde secuencias de tokens generadas durante rollout difieren de las usadas durante entrenamiento. Al propagar IDs de tokens y log-probabilidades sin cambios desde el backend de inferencia hasta el entrenador, ProRL Agent garantiza consistencia matemática—un requisito fundamental para algoritmos de aprendizaje por refuerzo estables.
Qué Observar La adopción de ProRL Agent podría acelerar el desarrollo de agentes autónomos en un orden de magnitud, particularmente en aplicaciones empresariales donde la integración con sistemas heredados es crítica. Empresas como Microsoft, Google y OpenAI—todas con inversiones masivas en agentes de IA—probablemente adoptarán arquitecturas similares dentro de los próximos 12 meses.
Observe cómo NVIDIA posiciona esta tecnología: no como un producto aislado, sino como infraestructura fundamental para su ecosistema de IA. La compatibilidad con vLLM y otros backends de inferencia sugiere una estrategia de plataforma que podría consolidar el liderazgo de NVIDIA en entrenamiento de modelos grandes más allá de hardware puro. El verdadero test llegará cuando laboratorios independientes publiquen benchmarks comparando ProRL Agent contra frameworks de código abierto—si la ventaja de rendimiento supera el 30%, el estándar de facto para entrenamiento de agentes podría cambiar permanentemente.
Tags


