La diferencia entre un asistente útil y una interacción torpe se mide en milisegundos. Salesforce AI Research acaba de lanzar una arquitectura que podría redefinir los asistentes de voz en bienes raíces.
El panorama general
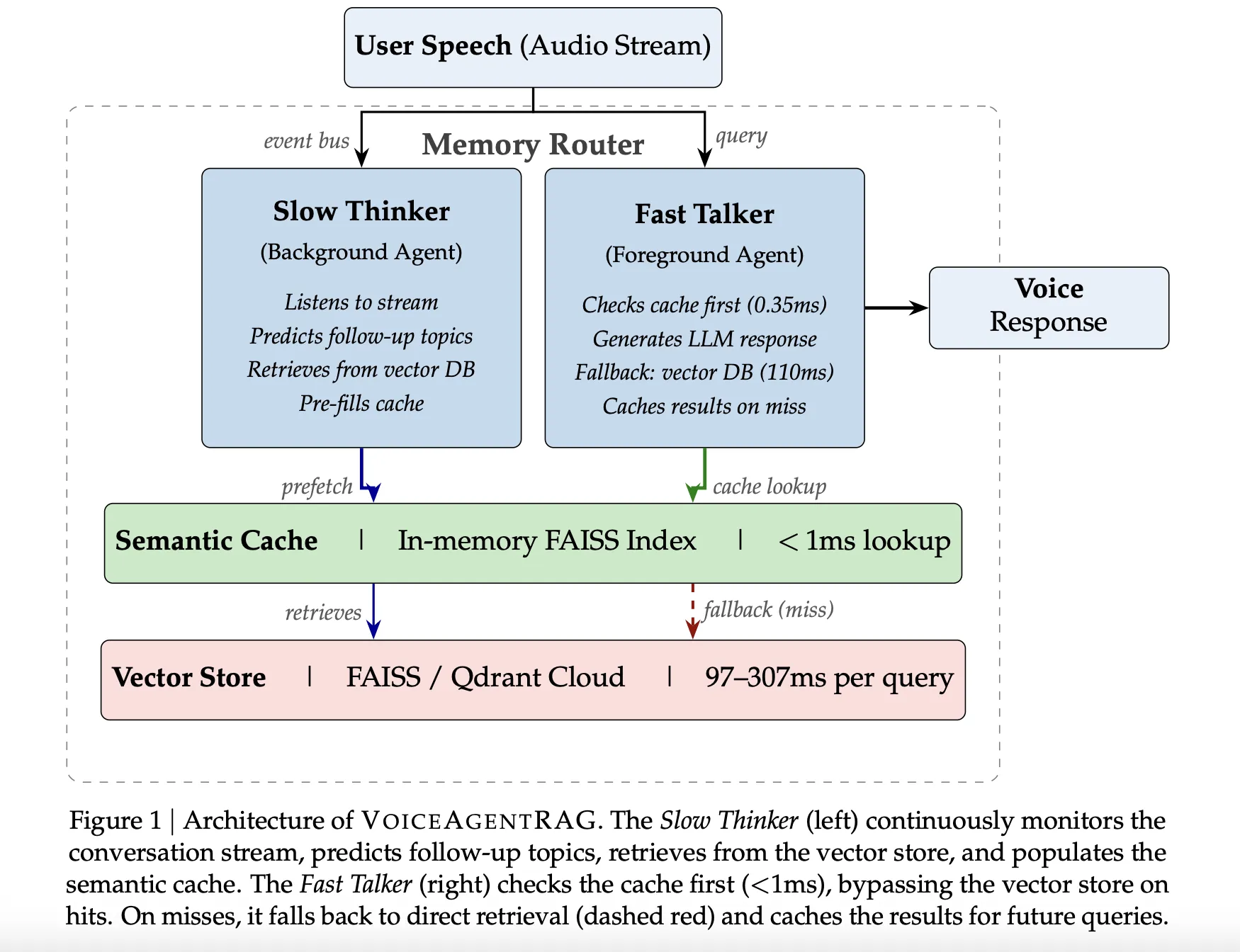
Los sistemas de voz tienen un presupuesto estricto: 200 milisegundos para mantener una conversación natural. Las consultas estándar a bases de datos vectoriales consumen 50-300ms solo en latencia de red, dejando poco tiempo para que el modelo de lenguaje genere una respuesta. VoiceAgentRAG resuelve este cuello de botella mediante una arquitectura de dos agentes que desacopla la recuperación de documentos de la generación de respuestas.
La investigación se evaluó con Qdrant Cloud como base de datos vectorial remota, utilizando 200 consultas y 10 escenarios de conversación. El sistema es de código abierto y compatible con los principales proveedores de LLM.
“Un sistema de dos agentes reduce la latencia de recuperación de 110ms a 0.35ms, una mejora de 316 veces.”
Por qué importa

En bienes raíces, los asistentes de voz podrían transformar la experiencia del cliente. Imagine preguntar sobre tasas hipotecarias, comparar características de propiedades o solicitar información sobre trámites municipales y recibir respuestas instantáneas y precisas. Hasta ahora, la latencia hacía que estas interacciones fueran incómodas o directamente inviables.

