Alibaba acaba de lanzar un modelo multimodal nativo que procesa texto, audio y video en una sola tubería. Esto no es solo otro avance técnico; es un movimiento estratégico en la carrera global por la supremacía de la IA.
El panorama general
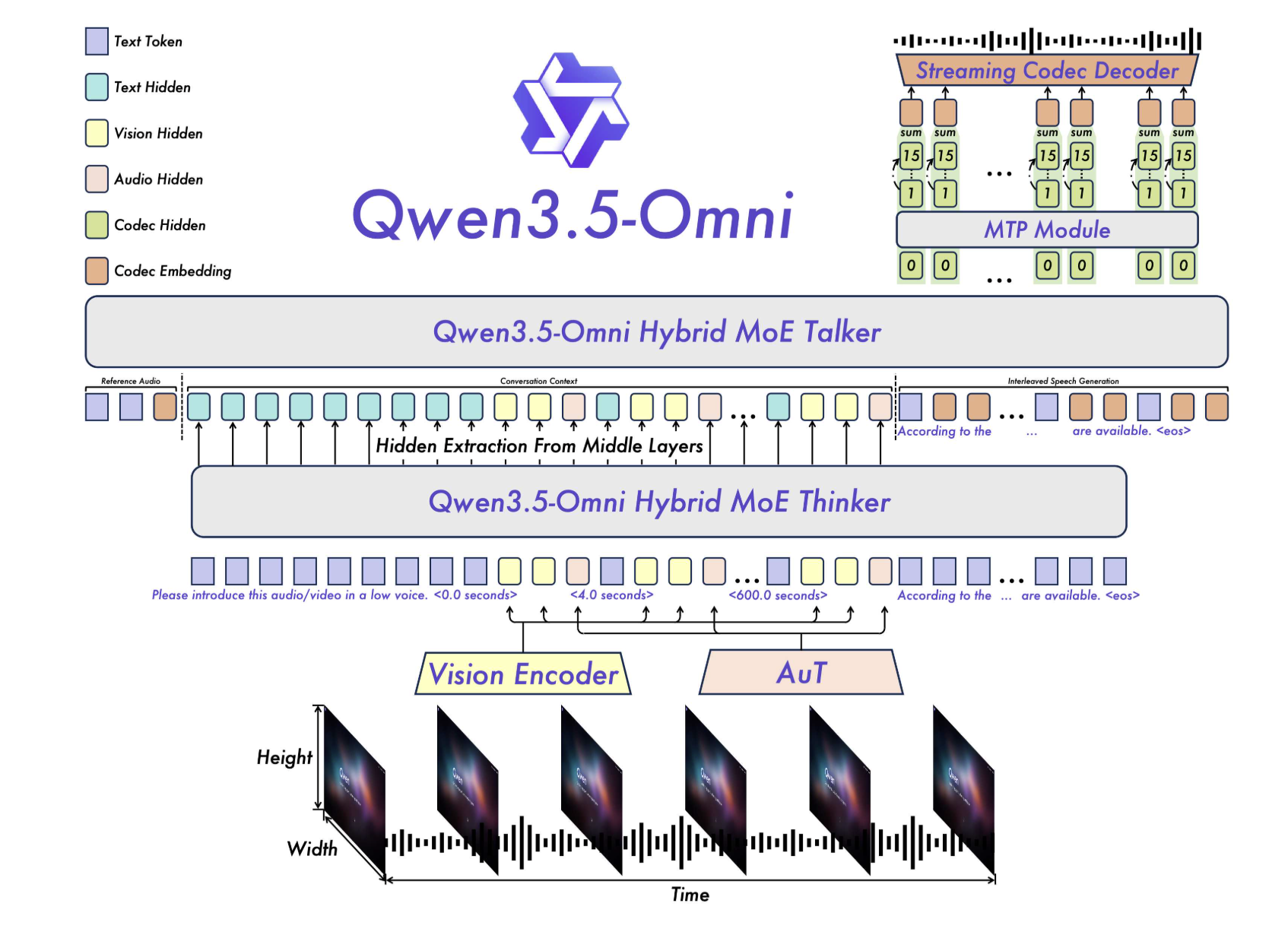
La evolución de los modelos multimodales ha pasado de ser experimental a convertirse en un campo de batalla clave para las grandes tecnológicas. Durante años, los modelos de lenguaje grande (LLM) se basaban en arquitecturas de 'envoltura', donde encoders separados para visión o audio se cosían a un backbone de texto. Este enfoque, aunque funcional, introducía latencias y limitaciones en la integración de modalidades. La industria ha estado buscando soluciones más elegantes y eficientes, especialmente con el auge de aplicaciones en tiempo real como asistentes virtuales y análisis de contenido en streaming.
Alibaba, a través de su equipo Qwen, ha respondido con Qwen3.5-Omni, un modelo diseñado desde cero para ser 'omnimodal'. No se trata de un parche tecnológico, sino de una reingeniería fundamental. Su arquitectura Thinker-Talker y el uso de Hybrid-Attention Mixture of Experts (MoE) permiten procesar múltiples modalidades simultáneamente dentro de un solo pipeline computacional. Esto posiciona a Alibaba directamente contra gigantes como Google y su modelo Gemini 3.1 Pro, marcando un punto de inflexión en cómo las empresas abordan la multimodalidad. En un mercado donde la velocidad y la precisión son críticas, este lanzamiento podría redefinir los estándares del sector.
“Un modelo que logra 215 resultados SOTA en tareas de audio y audio-visuales no es solo un logro técnico; es una declaración de guerra en la carrera de IA.”


